Slack search is a reverse network effect: it gets worse the more Slack is used. I’ve been doing customer research for my GPT-powered Slackbot, and my conversations keep surfacing huge pain points around Slack search.
Note: I’m going to use “Slack” as a synonym for Teams, Slack, Mattermost, Discord (the chat part) and other Slack-like chat collaboration derivatives. Slack was the first breakout success in this space.
Slack is a popular communication tool for businesses and teams. It (along with Teams) is the top chat-based collaboration software. I wouldn’t want to go back to the world pre-slack and teams, when gchat and skype chat (or just lots of emails) were the common real-time chat platforms. But Slack’s success has created it’s own problems.
The Problem
Much of a company’s context is implicitly stored in Slack. In some places I’ve worked, conversations are
defacto documentation, being a reasonable reference for otherwise poorly documented process or interfaces.
However, as the amount of stored history in Slack grows, finding what you need becomes
increasingly difficult. Slack’s search feature is notoriously unhelpful, all too often,
returning irrelevant results. It is especially frustrating to users to know that
the information you need is buried in Slack somewhere, but you can’t find it.
This is particularly problematic for teams that heavily rely on slack (distributed, remote, or just heavy users). Because Slack search is keyword based, and it’s “Most relevant” sort doesn’t seem to learn or improve with use, the more content you have in Slack, the worse search is.
Reverse Network Effect1
This is almost the opposite of how a lot of data-driven products work. The more you use a tool, the better it should get for your use-case. But with Slack, more content just means more potential false-positives for it’s keyword-based search engine. Keyword search is just as likely to find irrelevant content on a random, un-important channel as it is to find what you want.
I’m calling this the Reverse Network Effect. The more users there are on our Slack workspace, the worse the problem. You gain from the user-based network effect of having access to others, but a core piece of your tool gets worse.
Back when I was at Wayfair (and especially during the 100% remote pandemic times), I remember search for information often following this workflow.
- Enter initial keywords for content I was trying to find. [Failure]
- Try to refine keywords [Failure]
- Try to refine both keywords and the channel or author I thought was relevant [Failure]
- Sometimes remember a specific phrase or link that as added that should make my search more unique. [Some success]
- Resort to scrolling and rough time-based search (drop all keywords, search on time period)
Keyword Search
While I don’t understand the internal challenges and constraints of Slack, to have basically pure keyword search in 2023 is amazing, especially for an application built around conversations. For a lot of search, keyword-based search has long since disappeared. Semantic search, where modern deep-learning techniques are used to go beyond keywords and search based on meaning, can be powered by techniques as simple as word2vec.
Solution
External Solution
The hardest, but potentially most realistic solution to the Slack search problem is an external search provider. Linen will mirror entire workspaces for you, and could, if they wanted, try and provide better search (or Google-based search for open workspaces). Glean and Dashworks are two companies trying to offer better enterprise-wide search capabilities (though interestingly both companies seem to offer search bots for slack, not the consumption of Slack conversation content itself.)
Internal Solution
The best solution would probably be an internal solution. Introduce semantic search, and try to improve relevancy scoring. The most relevant conversation for me is almost always one I’ve seen before, and failing that, is one in a channel of which I’m a frequent participant. Collect more data about my usage and introduce stronger ML-based sort. Have I seen the message? Did I participate in the conversation? Do I frequent the channel? Etc.
All of this is personalized. All of this requires data. Data requires infra and storage and cost. But due to that data, an internal solution has the best chance of being highly successful.
Example
Let’s say you worked at Meltano, and you remember a conversation about slow data flow into Google BigQuery. For reference, here is the conversation I’m trying to find.
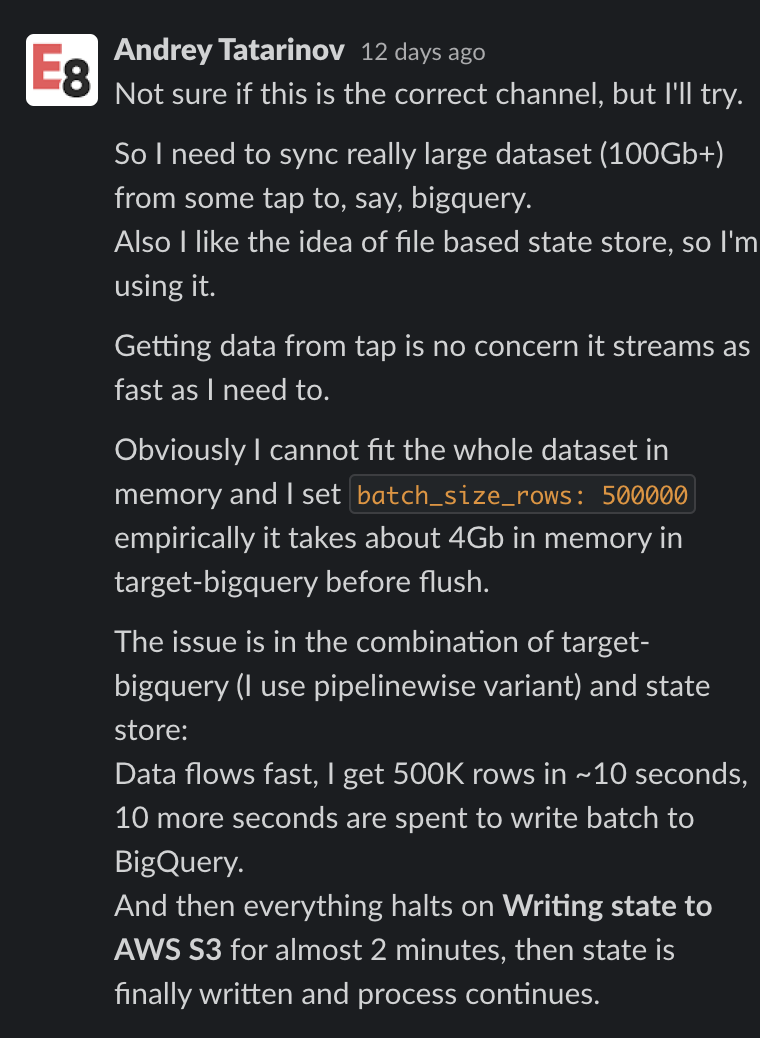
Search: bigquery slow
Now, I know the issue was related to BigQuery ingest being slow, so I start simple. “bigquery slow”. This doens’t work because “slow” isn’t actually in the conversation.
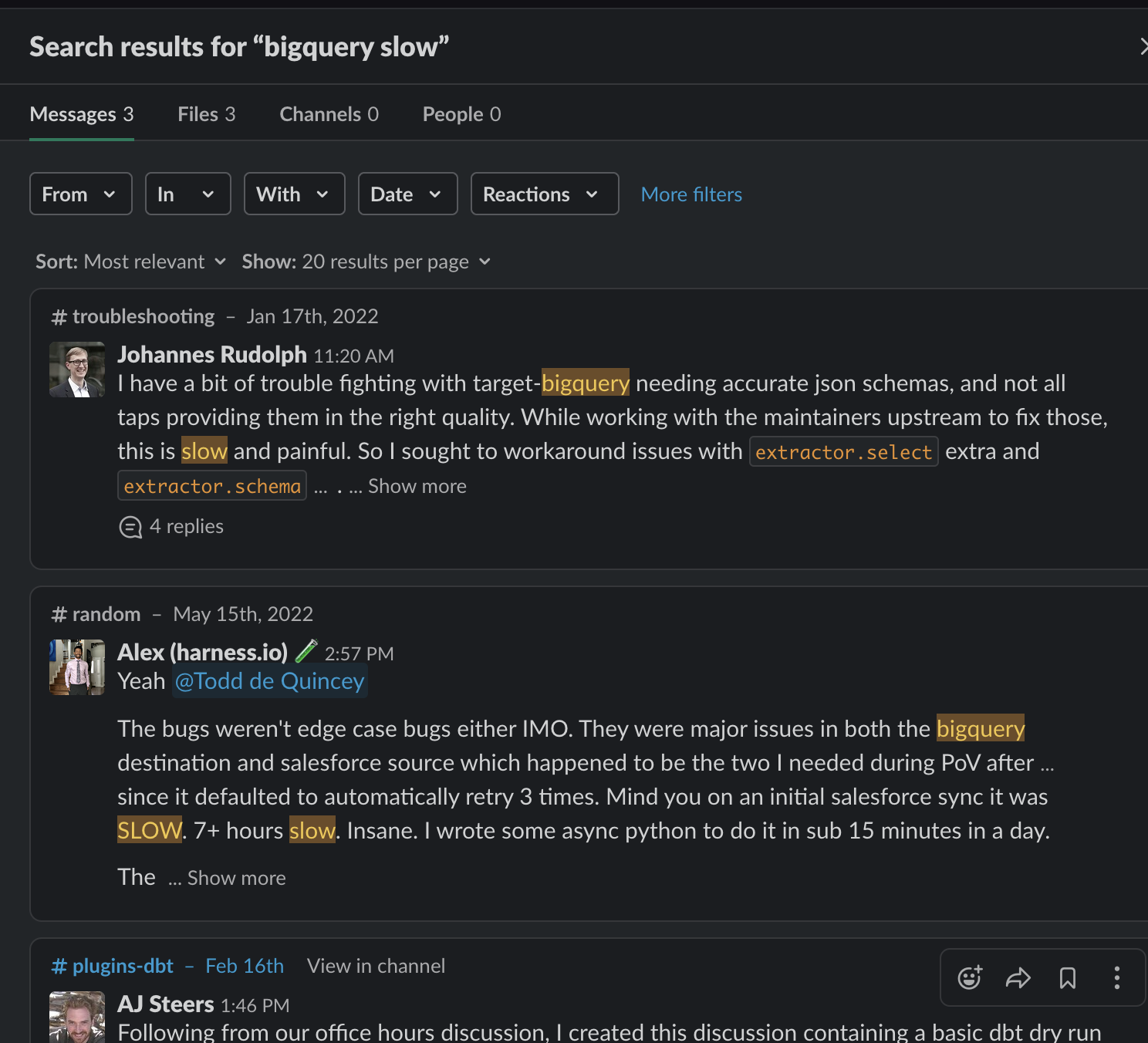
Search: bigquery throughput
Now maybe I think: They were talking about throughput issues, so let’s search on that.
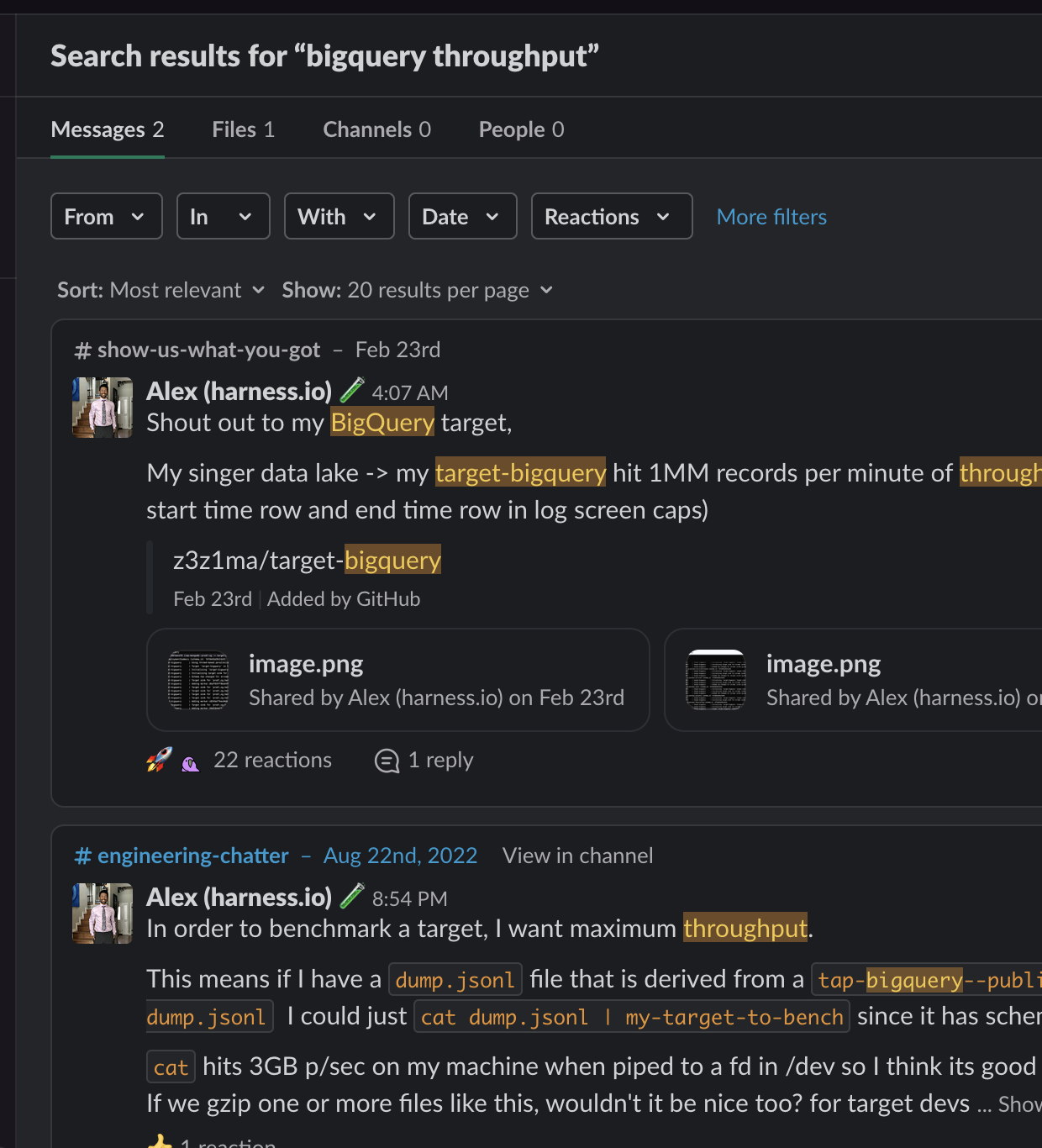
Nope. While the word throughput was in the conversation, that word didn’t co-occur with BigQuery in the same message. As any Wisconsin mother would say, Oofta.
Search: bigquery
Ok, brute force, this isn’t working. Let’s just drop down to bigquery.
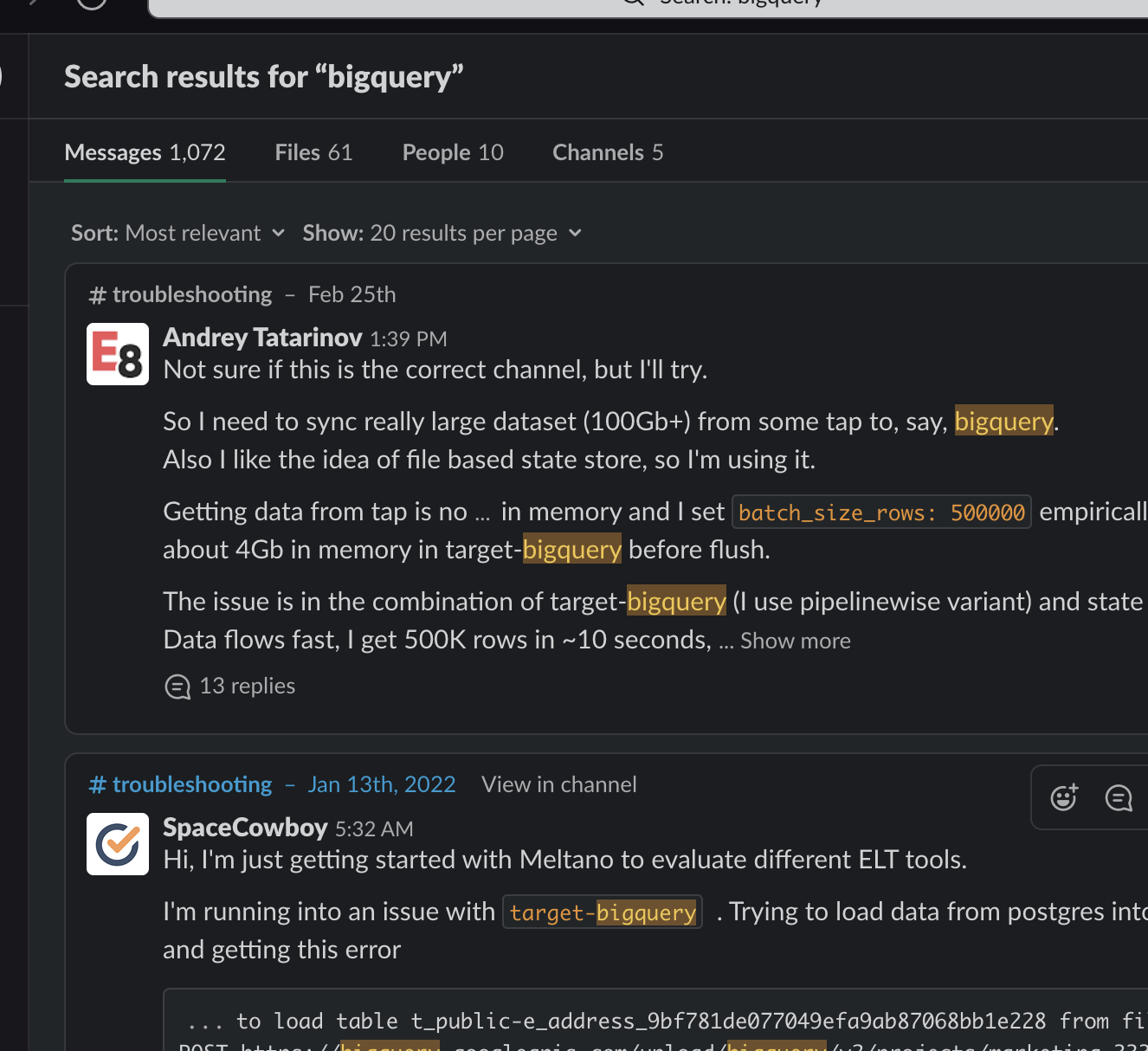
Success! Sort of. Because Slack search has a strong recency bias, my target conversation comes to the top. But if the message had been older, it would have been lost in the 1072 (!) messages that mention bigquery. The search may have been saved if I remembered the channel or original person posting the message, but in my experience, memory can be unreliable and such filters cause as much problems as they help.
Conclusion
Slack search is rough. It gets worse the larger the organization. In my customer interviews, poor Slack search is frequently quoted as one of the top pain points.
-
It’s a reverse scaling law or something, network effect feels a bit innacurate here, but it gets the sentiment across IMHO. ↩